驰声科技沈来信:AI+K12语言教育还有多少想象空间?
2018.11.14

芥末堆 小筱 11月14日 报道
11月14日,在以“碰撞·演变”为主题的GET2018教育科技大会“K12教育科技企业的‘军备竞赛’ ”分论坛上,驰声科技首席科学家沈来信发表了题为《AI+K12语言教育,还有多少想象空间》的主题演讲。
沈来信从智能语音技术如何能更好的服务K12的教学场景?AI在K12的语言教育里面除了评测还能做什么等问题进行分析,并分享了驰声科技未来的打算。
以下是演讲内容实录:
人工智能这两年非常的火热,但是今年下半年开始有一点降温。大家开始理性的思考,应该讲人工智能还是像前面几位嘉宾讲的一样,它仅仅是一个技术,它应该是没有能力取代、颠覆我们的教育的。所以我们要根据我们的内容和技术结合在一起,形成一个很好的产品。

驰声是专注于语音评测的,从2008年开始到现在将近有十年的经历了。我们从2007年的中文的发音能力评测到2008年无插件声调的评测以及英文发音能力评估,到后面的音素、重音、单词和句子等等。一直到2013年的时候有相应的发音能力评估以及2015年支持微信和英语表达能力的评估,主要是立足于口语这一块的评测和反馈。
目前我们服务的客户有132个国家和地区,每年会有500万以上小时的录音数据,800万台的离线评测的PC、手机、ipad的离线评测。我们服务的客户包括像培训行业,出版行业,还有互联网智能设备、智能软件以及教育、政府机构。
我们一直在思考,智能语音技术如何能更好的服务K12的教学场景,所以这里面我们定义了三个场景:正式考试环境下如何根据人工定标的数据,它的标准进行自动的评分,我们提供了一个AMS,目前已经服务了多个地区;在考辅里面,有备考和模考的环境,要辅助校园的测试,提供了一个CESE的评测和考试的标准;在课外,包括学生在家庭里自学进行的一些单词、句子、段落、发音、能力的评估。
AI在K12的语言教育里面除了评测还能做什么?目前我们可以进行打分,性能也是超越了人工的评分,在业界同行里面具有相当的竞争层次。在评测的基础上还能做什么呢?在客户使用过程中我们发现,大量用户发音的时候总是不断的犯错,有的学生反馈“我的孩子都快读哭了还读不到满分”;有的孩子说“今天读不到一百分就不睡觉”,因此不断的读,但是不断的犯同样的错误。因此我们提出了这样一个路线,不光提供评分的情况,而且要给它进行诊断,发现他在哪个位置发生了错误,以及如何纠正,给出一个反馈和指导,我们根据这个路线进行研发技术和产品,真正做到了以评促教、以评促学。
我们在去年一年主要在两个方面有开创性的成果,完成了从评测到诊断,到指导反馈的闭环,发布了两项开创性的技术。
发音纠错检错的功能。目前我们市场上有些可以替换的错误,有读错的检测,这也是有产品的,但是有些多读和漏读的错误现在是没办法检测出来的。因此我们构建了一个扩展网络的形式,可以支持任意单词的音素级插入、删除和替换错误。我们这种网络是在lab,三个音素的情况下,任何一个音素的前后都可以任意的插入也可以删除,而且也可以替换这三个错误。目前评分的性能是比较高的。

这是一个音素级的分析,match如果发音错误会有相应的提示,有相应的指导,怎么样正确的发音。整个评分会更加准确,以扩展网络的形式;诊断更细致,在音素级别发现学生的发音规律;指导更有效,可以对他有针对性的进行指导,特别是易混淆音的发现,让用户不断的练习,提高在这方面的辨别能力;相应的报告进行呈现,对他进行综合能力的评估。这是英文发音纠错的闭环情况。
第二个是我们在评分的时候,在考试系统里和校园版的考辅系统里面发现,以前都是通过定标数据进行黑盒的评分,用一个逻辑回归的方式或者是SVR的方式拟合一个分数,但是并不清楚分数整个拟合的过程。因为我们对于很开放型的题目,从总分里面分出了四个维度,包括内容的得分、发音的得分、语法的得分、流利度的得分。在内容得分里面包含了说的内容、主题、关键词等进行相似度的计算。发音会根据发音的特征,提取他的特征,经过一个拟合的公式,拟合出他的发音来。
得到这四个维度以后我们也不再用以前的,直接是现象级的方式拟合了。用(乐贝格)的方式进行公式化的拟合,让拟合方式更加透明。目前这个性能远远高于以前的基于特征直接拟合总分的情况。这个好处是不仅性能提升了,而且为后期打下了一个伏笔。目前我们在这四个维度上都在继续往下做,对应着诊断和反馈,你的语法错在什么位置、什么类型,应该纠正成什么样的类型。
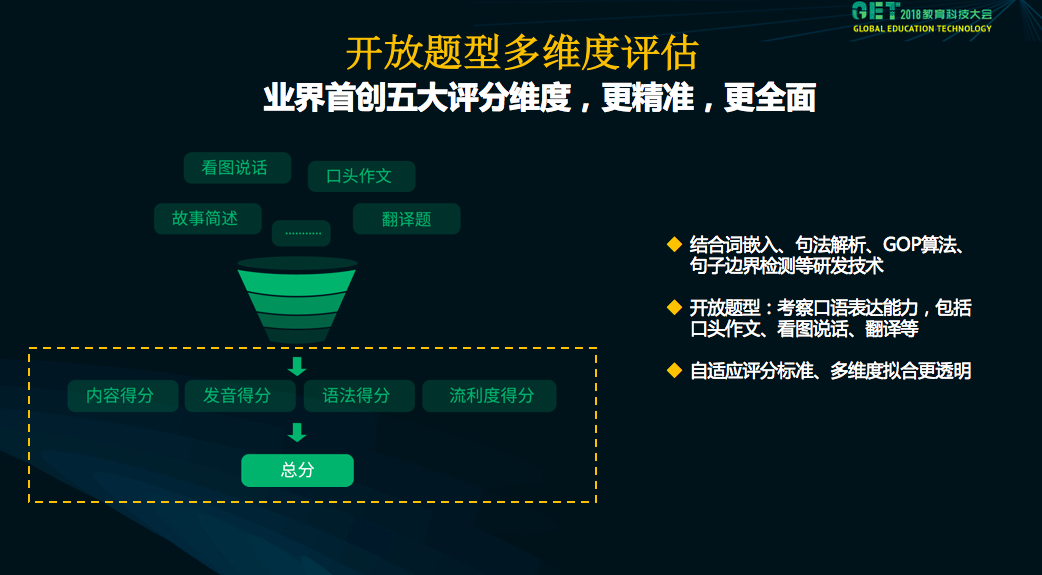
这是第二个,里面结合了研发的一些技术,词嵌入技术、句法解析、GOP算法等等。目前支持开放题型包括口语作文、看图说话、翻译等等。最主要的特点是自适应的评分标准。不同的地区对这四个维度有不同的侧重点,根据定标数据可以学习到在每个维度上的特征、每个维度上的权重。根据这个权重拟合出一个比较适合该地区的评分标准,所以整个拟合过程会更加透明。
我们在语音识别和评测的基础上会做很多基础研究,会做一些声学模型的改进。主要是为了识别更加准确,这里面使用了深度学习的架构,包括DNN、TDNN、传感识网络、LSTM、GRU等等,我们增加了一些门机制、注意力网络等等,去提升它的性能,这是一个长期要做的工作。
第二个是在迁移学习的应用。我们在一个新的地区,在不同的应用环境下如何能够快速的做当地基于少量标注数据的声学模型的自适应呢?就用迁移学习的方式完成,用权重迁移和模型迁移,可以很快速的在一个新地区完成语音识别的部署。
第三个是数据声学的筛选,我们以前需要标数据,现在不需要标数据了,它的文本都不再标了。采用数据筛选的方式进行处理,这里会基于基于置信度和解码网络的方式筛选数据。前期我们在某地区有三千小时的考试数据,通过这个网络选择了900小时的很高质量的数据可以完成该地区的升学模型的自训练,可以快速的匹配我们的产品。
第四个我们也会做一些工作,包括音标和音素的自动生成,有些产品会需要根据考生的文本自动的生成对应的音素序列,还有出版社希望所有的单词给出它的音标序列。目前采用的是G2P的模型,给出一个文本,自动的这两方面的生成。这是第三个方面的一些研究。
在最后我们分享一点AI+K12的语言教育,最终我们未来还有哪些打算?通用识别这一块会继续加强.这里会扩展到一个智能问答,在各种环境下我们希望做一种智能问答的场景.这里面就涉及到通用识别的情况;评分里面有答案的自动生成、自动扩展提高评分性能。
语音的自动分类,我们期望基于不同的地区、不同的人群自适应一个评分标准,大中小城市他们之间的评分标准还是略有差异的,我们希望它在本地区进行同地区的评比、评测、能力的评估。
虚拟教师的情况,启用一个一对一的教学环境,在对话的过程中进行发音的、语法的、流利度等方面的指导和反馈,让学生进行自由的交互。特别是基于图像、基于语音、自然语言的三种方式。像作业帮手一样,帮助学生进行课外的辅导和智能问答。
我们希望扩展自适应学习的架构,目前我们基于知识图谱做各个年级,学生在词汇、语法、听力、阅读和写作等五个维度上所具有的能力,然后进行横向和纵向的扩展。
总的来说,还是我们前面说的,人工智能目前也是发展的比较快速,在图像、语音、自然语言上都有很大的突破,因此它会给我们带来很大的动力。但是我们一直认为,内容是更加接近于我们教育的,让技术成为内容的好帮手,形成一个好的产品去提高学生的个性化学习以及自适应学习的基于兴趣的、基于单体的学习机制,让我们开发出比较适应于学生的个性化方式的一种产品出来。我们也希望技术、产品和内容能够很好的结合,最后形成一个相应的结果。

在印象笔记里轻松做会议记录吧~
|
印象笔记是一款风靡全球的免费笔记应用,是全球 2 亿人的工作空间。你可以使用任何一台设备打开印象笔记,在这里专注完成写作、收集有用信息、快速发现所需、随时演示想法。
|
|
新技能get√
长按并识别以下二维码,关注【我的印象笔记】微信号,即可永久保存嘉宾完整分享内容。 |
